因为英特尔,我们知道了CPU;因为英伟达,我们对GPU充满了兴趣;也是因为英伟达,DPU开始进入大众的视线。在当今算力时代的大趋势下,DPU芯片将大有可为,它有可能成为继CPU和GPU之后的第三颗算力芯片,CPU做不好,GPU做不了的计算负载将由DPU来承担。这也引得如英特尔和英伟达以及云供应商阿里、亚马逊、微软等巨头们纷纷竞折腰。那么国内在DPU领域的进展如何?他们又该如何在这新一轮计算革命时代,把握住这个机遇。
DPU(Data Processing Unit的缩写)也就是所谓的数据处理单元。它是最新发展起来的专用处理器的一个大类,为高带宽、低延迟、数据密集的计算场景提供计算引擎。那么DPU是怎么产生的呢?本质原因还是需求驱动。据IDC统计,近10年来全球算力增长明显滞后于数据的增长。每3.5个月全球算力的需求就会翻一倍,远远超过了当前算力的增长速度。算力,成为先进生产力,承载了十万亿美元规模经济。计算组织从“端-云”一体,到“端-边缘-云”一体;再加上从存内计算到网内计算,出现大量可以从CPU卸载任务;通用、专用的体系架构并举孕育了DPU的机遇。算力源于芯片,目前数据中心中核心算力芯片包括CPU、GPU、FPGA和少量ASIC,其中各类通用CPU占比还是绝对统治地位。根据Nvidia和初创公司Fungible的预测,用于数据中心的DPU量级将达到和数据中心服务器等量的级别。服务器每年新增大约千万量级,每台服务器可能没有GPU,但一定会有一颗或者多颗DPU,好比每台服务器都必须配网卡一样。而且服务器每年新增大约1500万台,每颗DPU如果以1万元计算,这将是千亿量级的市场规模。那么DPU和CPU、GPU该如何相处?通俗来说,如果把一台计算机或服务器比作一个团队,CPU相当于这个团队的“大管家”,负责思考并处理各种业务;GPU是“美工”,专攻图像处理;DPU则相当于“前台”,负责打包、拆包“数据包”,提升整个团队的工作效率。具体来看,CPU负责构建应用生态,GPU负责图像处理核深度学习训练,DPU负责卸载基础层应用,比如网络、安全、数据压缩等。CPU、GPU、DPU三者共同构成了计算基础设施。但从结构上来看,DPU会更异构、也更专用。那么DPU究竟能做哪些?有哪些核心的优势?DPU可作为CPU的卸载引擎,释放CPU算力到上层。DPU还将成为新的数据网关,将安全隐私提升到一个新的高度。DPU将成为存储的入口,将分布式的存储和远程访问本地化。DPU将成为算法加速的沙盒,成为最灵活的加速器载体。
DPU广阔的市场空间,许多人都想来分一杯羹,这在国外厂商中尤其激烈。目前DPU主要厂商有Intel (收购Bearfoot), Mellanox(已被Nvidia收购),Marvell(收购了Cavium),Broadcom, Fungible(初创),Pensando(初创)等,但是每家的DPU都不太一样。Intel是基于FPGA实现的,主要面向交换机、路由器芯片;Broadcom基于Arm实现,也是主要面向交换机、路由器芯片;Marvell通过收购Cavium,基于Arm实现,主要面向5G的基带;初创公司Pensando通过软件定义网络处理器,主要面向支持 P4的SDN;另外一家初创公司Fungible基于MIPS实现,主要面向网络、存储、虚拟化;Nvidi收购Mellanox的网络方案,其他功能基于Arm实现,主要面向数据安全、网络、存储卸载。总体来看,实现的方式主要有三种,通过增加以下内容来提高其计算能力:方法一,收集许多Arm核心;方法二,增加流处理核心(FPC),这是一种是自定义设计的网络处理器,通常为P4;方法三,增加现场可编程门阵列(FPGA)。
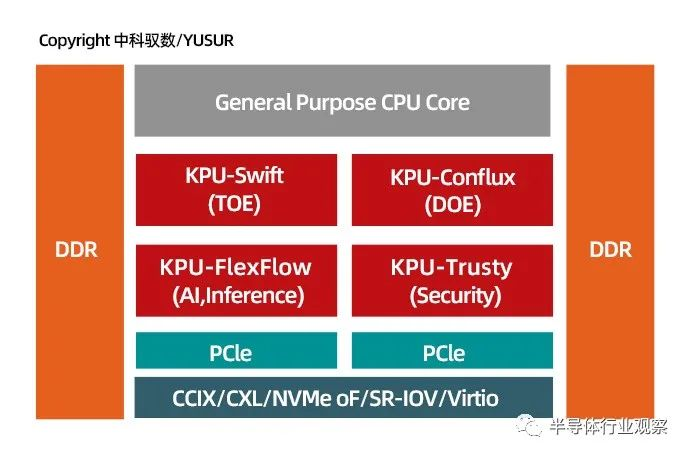
国内最近也涌现了一批DPU的玩家,本次我们要说下脱胎于中科院,在DPU领域布局多年的中科驭数。他们又是怎么来玩转DPU这个新兴事物的。中科驭数的创始团队在国内较早进行DPU芯片研发,创始人兼CEO鄢贵海博士、联合创始人兼CTO卢文岩博士及首席科学家李晓维博士均来自中科院计算所计算机体系结构国家重点实验室,堪称体系结构方面“国家队”级别团队,在芯片架构领域有15年的技术积累。他们创新性提出了软件定义加速器技术(Software Defined Accelerator),自主研发了KPU(Kernel Processing Unit)芯片架构,2019年设计了业界首颗数据库与时序数据处理融合加速芯片,已经成功流片。不同于Broadcom,Fungible等厂商,中科驭数将重点放在了异构核上,而没有采用原来众核为主的架构,即以针对性算法加速为核心,驭数提出了KPU架构来组织异构核。中科驭数在提出KPU架构时认为,异构计算就应该用异构核来做。所以驭数的DPU更加的“专用”,也更加的高效。KPU架构是中科驭数创始团队近十年在体系结构方面研究成果和研发经验的积累。其相较于传统的ASIC或SoC DPU芯片架构,具有极高的灵活性,可以通过即时的软件配置来定义芯片内部数据运算逻辑,在保障充沛算力的同时,以最低功耗支撑更多运算负载类型。中科驭数DPU的核心特征总结为三点:连接(Connecting)、卸载(Offloading) 和虚拟化(Virtualizing),简称COV。目前中科驭数已经积累了8个大类的KPU内核资源, 涵盖了时间序列分析、数据查询、加密解密、数据压缩、协议解析等,并在过去两年完成了两代KPU的迭代。KPU也从最初的单个应用算法加速,进化到了集网络、数据库与应用算法的全方位立体化加速体系。在KPU架构下,中科驭数研发了国内首款芯片级完善的L2/L3/L4层全网络协议处理核,推出了直接面向OLAP、OLTP及类SQL处理的数据查询处理核,而没有采用原来众核为主的架构。”据鄢贵海介绍,异构核架构将带来更高效的数据处理效率、获得更直接的使用接口,以及更佳的虚拟化支持。以KPU架构为核心,在2019年流片第一颗芯片的基础上,中科驭数宣布了其下一颗DPU芯片研发计划,功能层面包括完善的L2/ L3/L4层的网络协议处理,可处理高达200G网络带宽数据。其次融合数据库、大数据处理能力,直接面向OLAP、OLTP及大数据处理平台,如Spark等。另外还囊括机器学习计算核以及安全加密运算核。该颗芯片预计将于2021年底流片。中科驭数的DPU可以广泛应用于金融交易,大数据查询,数据安全,分布式计算加速等应用中,在未来,驭数的DPU还可以拓展到大量云计算、边缘计算场景,为V2X,AIoT等业务提供更加高效的算力芯片选择。在中科驭数看来,DPU是一个重设计和应用的方向,如CPU一样,重视生态建设和应用支撑,DPU是基础层的应用支撑,是发展的关键点,和产业发展方向符合。