喜欢0次
团队:芯光 队伍编号:CICC1787

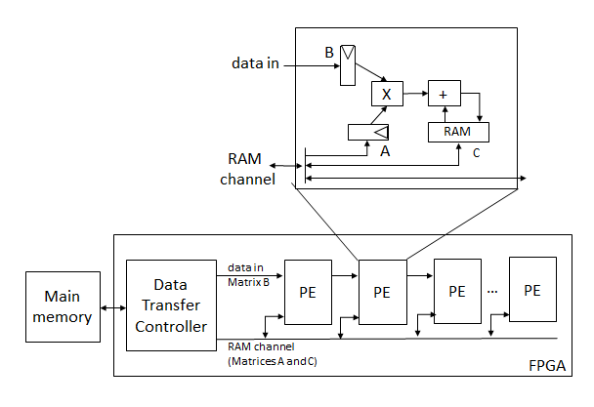
图1
为了高效的处理子矩阵块,我们对该算法进行了优化。确定子矩阵块大小(Sp×St1)后,直接在片上初始化子矩阵C为零矩阵,即把分配给子矩阵块C的RAM块的数据置零。在子矩阵块计算完成后,将最终结果搬移到外部存储器中,并重新初始化子矩阵C为零矩阵,如此反复。精简前后的算法对比如算法1和算法2示,这种方式每次减少了Sp×St1大小的浮点数据传输,因此,我们可以把有限的访存带宽用到其他数据传输上。