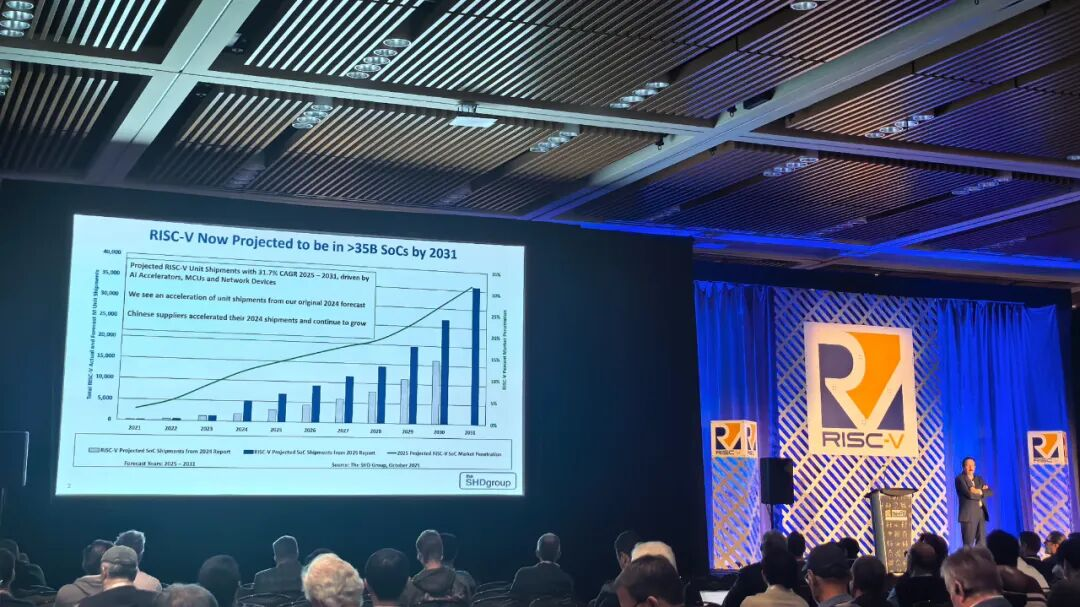
喜欢2次

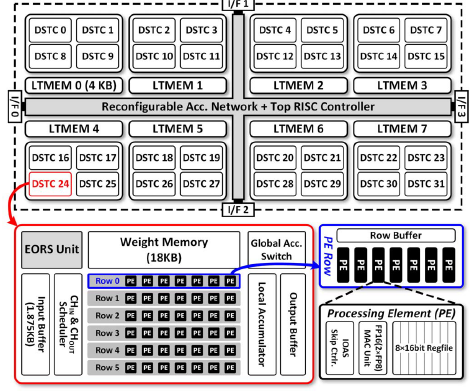
这篇文章实现了一个灵活的神经网络训练加速器,主要创新点如下:
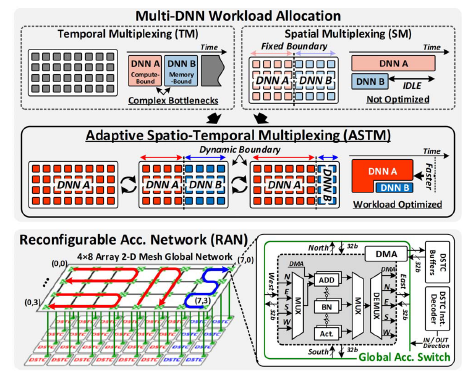
1. ASTM:自适应时空负载复用(使用RAN 可重构累加网络,提高单元利用率)
3. EORS:仅指数的 Relu 推理(预测未知的 ofmap 稀疏性,使用weight和act的指数部分预测结果是否为负值)
其架构具有一下特点:
1. 8个长期存储(LTMEM),32个双稀疏训练核(DSTC),每行PE共享10个单位的Row buffer,存ifmap,每个PE有8个存储,存psum,PE计算的结果交给 Local Acc 进行进一步累加;
2. 可配的全局累加网络 RAN,可以改变数据流方向,阵列上并行处理多个任务
3. 寄存器较少、算力高,片上网络灵活
笔者认为 ASTM 与 RAN 技术比较实用,具体原理如下图所示:
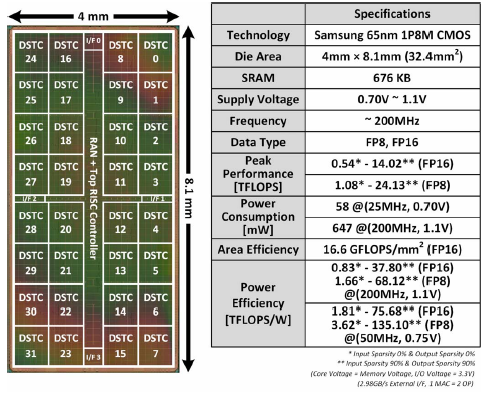
最后给出该加速器的性能数据:
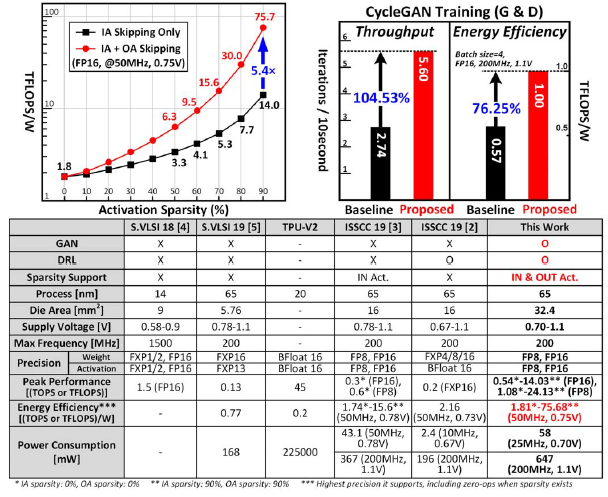
- 峰值算力:两种格式、有无稀疏
- 能效:(下面的更详细)低压和高压,有无稀疏、两个格式
- 功耗:低压低频、高压高频
- 原文给出了单次推理的耗能、推理帧率