喜欢2次
大家好,我们团队的名字是Hey Siri,参赛编号是CICC1584,最近学校开设的FPGA机器学习课程正好有讲到神经网络加速器的设计方法,我们团队的思路是做神经网络通过协处理器连接到蜂鸟的核上,学习课程之后感觉受益匪浅,对我们的协处理器硬件设计帮助很大,这次来分享一些相关的设计思路。
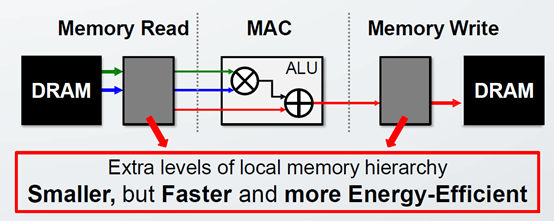
1. 利用本地存储
参考 CPU 的多级存储,在片内增加多级存储,类似于 Cache ,利用片上 Memory 存储部分数据,做到数据复用,减少访问 DRAM,越是靠近 ALU 计算单元的速度越快,效率越高(存储空间越小)。
2. CNN中存在数据复用
如图所示,CNN 滑动卷积: 2D 卷积核和滑动窗口内 2D ifmap 点积,每一个卷积核权重复用了 E*E 次,每一个输入 ifmap 点复用了 R*R 次(same 方式)。
现有的数据复用方式如下所示,把某一种数据固定在某个层次的存储器中,直到完成所有计算。
l 权重固定 Weight Stationary (WS): 权重保留,完成和每个滑动窗口对应输入的乘加以后再加载。复用 E*E 个计算,最多复用 E*E*N ( 多批次)。
l 输出固定 Output Stationary (OS) : 乘加以后的部分和 psum 保留,直到完成整个 2D或 3D 滑动窗口计算再写入内存,最多复用 R*R*C 次,完成一个输出特征图像素。
l 输入固定 Input Stationary (IS):输入特征图保留不变,完成和所有相关卷积核点积以后再加载,最多复用 R*R*M 次。
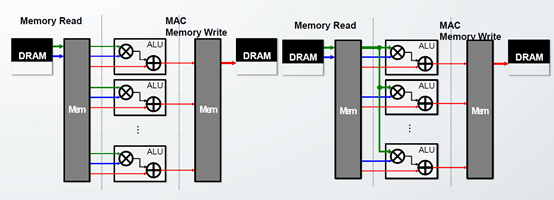
3. 不同网络模型的效果
如图所示,后者相对于前者,减少了连线资源和复杂度。
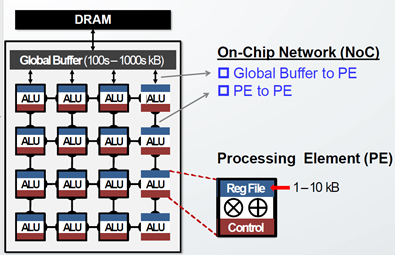
4. DNN加速器空间架构片上存储设计
全局 buffer (SRAM),用于缓存 DRAM 中的数据以便快速使用,一般在 100~300KB 左右。再在每个 PE 中加入控制逻辑和寄存器缓存临时结果。通常全局 buffer 的1/100。片上总线实现 GLB 到 PE PE 和 PE 之间的互联,在接口设计 FIFO 存储。
不同层次的存储的功耗相差很大,以 ALU 计算功耗为参考,DRAM 访问一次能耗是访问 RF 一次的 200 倍,所以设计多层次访存的目的也是为了减少高层次数据访问的开销。
如果一个输入数据值被重复用于许多操作,理想情况下,该值从 DRAM 移到 RF 一次, ALU 从 RF 多次读取。然后由于存储限制, GLB/FIFO/RF 容量有限,所以需要在更高一级存储缓存。卷积计算中 Ifmap 和 filiter 数据都是通过多级存储读取加载卷积计算中 Psum 数据需要从更高一级存储中反复读写。
最佳的数据流设计,高层级存储器访问次数越少越好。
这篇贴子分享了一些设计神经网络加速器的技巧,通常的神经网络运算量很大,采用一些资源复用可以有效地提升网络的性能,能力有限,难免出现疏漏,我们也是在学习,有些理解不到位或者错误的地方希望大家能够指正,共同学习共同进步,祝各参赛队比赛顺利!