喜欢0次
大家好,我们团队的名字是五四芯青年,报名编号为CCIC1659,想结合最近的学习,对于神经网络中的激活函数进行一个总结。水平有限,如果有错误希望大家多多批评指正。
神经网络中使用激活函数来加入非线性因素,提高模型的表达能力。
如果不用激励函数(其实相当于激励函数是f(x) = x),在这种情况下你每一层节点的输入都是上层输出的线性函数,很容易验证,无论你神经网络有多少层,输出都是输入的线性组合,与没有隐藏层效果相当,这种情况就是最原始的感知机(Perceptron)了,那么网络的逼近能力就相当有限。正因为上面的原因,需要引入非线性函数作为激励函数,这样深层神经网络表达能力就更加强大(不再是输入的线性组合,而是几乎可以逼近任意函数)。
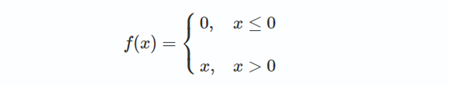
ReLU公式近似推导:

下面解释上述公式中的softplus,Noisy ReLU。
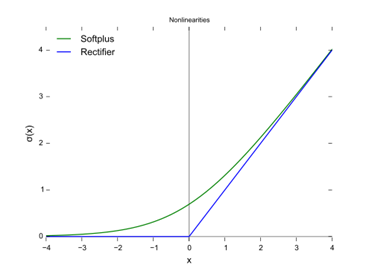
softplus函数与ReLU函数接近,但比较平滑,同ReLU一样是单边抑制,有宽广的接受域(0,+inf),但是由于指数运算,对数运算计算量大的原因,而不太被人使用。并且从一些人的使用经验来看,效果也并不比ReLU好。
softplus的导数恰好是sigmoid函数,softplus函数图像如下:
ReLU可以被扩展以包括高斯噪声(Gaussian noise):
f(x)=max(0,x+Y),Y∼N(0,σ(x))
Noisy ReLU 在受限玻尔兹曼机解决计算机视觉任务中得到应用。
ReLU上界设置: ReLU相比sigmoid和tanh的一个缺点是没有对上界设限.在实际使用中,可以设置一个上限,如ReLU6经验函数: f(x)=min(6,max(0,x)).。参考这个上限的来源论文为:Convolutional
Deep Belief Networks on CIFAR-10. A. Krizhevsky
当前,深度学习一个明确的目标是从数据变量中解离出关键因子。原始数据(以自然数据为主)中通常缠绕着高度密集的特征。然而,如果能够解开特征间缠绕的复杂关系,转换为稀疏特征,那么特征就有了鲁棒性(去掉了无关的噪声)。稀疏特征并不需要网络具有很强的处理线性不可分机制。那么在深度网络中,对非线性的依赖程度就可以缩一缩。一旦神经元与神经元之间改为线性激活,网络的非线性部分仅仅来自于神经元部分选择性激活。
对比大脑工作的95%稀疏性来看,现有的计算神经网络和生物神经网络还是有很大差距的。庆幸的是,ReLu只有负值才会被稀疏掉,即引入的稀疏性是可以训练调节的,是动态变化的。只要进行梯度训练,网络可以向误差减少的方向,自动调控稀疏比率,保证激活链上存在着合理数量的非零值。
1)
坏死: ReLU 强制的稀疏处理会减少模型的有效容量(即特征屏蔽太多,导致模型无法学习到有效特征)。由于ReLU在x < 0时梯度为0,这样就导致负的梯度在这个ReLU被置零,而且这个神经元有可能再也不会被任何数据激活,称为神经元“坏死”。
2)
无负值: ReLU和sigmoid的一个相同点是结果是正值,没有负值。
当x<0时,f(x)=αx,其中α非常小,这样可以避免在x<0时,不能够学习的情况:
f(x)=max(αx,x)
称为Parametric Rectifier(PReLU),将 α 作为可学习的参数。当α从高斯分布中随机产生时称为Random Rectifier(RReLU)。当固定为α=0.01时,是Leaky
ReLU。
1)
不会过拟合(saturate)
2)
计算简单有效
3)
比sigmoid/tanh收敛快

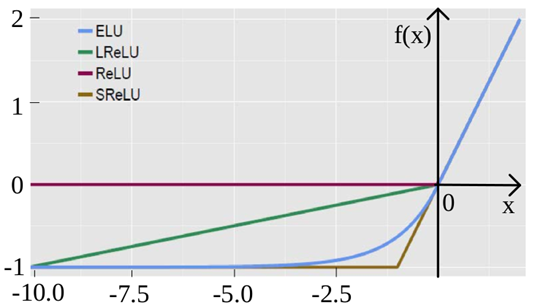
exponential linear unit,该激活函数由Djork等人提出,被证实有较高的噪声鲁棒性,同时能够使得使得神经元的平均激活均值趋近为0,同时对噪声更具有鲁棒性。由于需要计算指数,计算量较大。
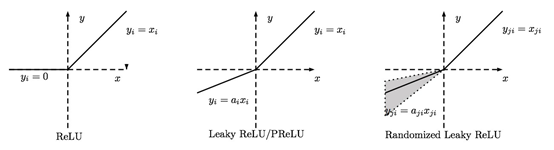
Leaky ReLU α是固定的;PReLU的α不是固定的,通过训练得到;RReLU的α是从一个高斯分布中随机产生,并且在测试时为固定值,与Noisy ReLU类似(但是区间正好相反)。
1943年,心理学家Warren McCulloch和数理逻辑学家Walter Pitts在合作的《A logical calculus of the
ideas immanent in nervous activity》论文中提出并给出了人工神经网络的概念及人工神经元的数学模型,从而开创了人工神经网络研究的时代。1949年,心理学家Donald Olding Hebb在《The Organization of Behavior》论文中描述了神经元学习法则。
人工神经网络更进一步被美国神经学家Frank Rosenblatt所发展。他提出了可以模拟人类感知能力的机器,并称之为‘感知机’。1957年,在Cornell航空实验室中,Frank Rosenblatt成功在IBM 704机上完成了感知机的仿真。两年后,他又成功实现了能够识别一些英文字母、基于感知机的神经计算机——Mark1,并于1960年6月23日,展示于众。在感知器算法中,激活函数是一个简单的单位阶跃函数(unit step
function),有时也叫赫维赛德阶跃函数(Heaviside step function):
随着人工神经网络快速发展,研究人员都对其研究,演化出更多的,更加复杂的,更深的神经网络来提高精确度。而激活函数的不同也会导致过拟合等问题。现在我们看看经典的神经网络中使用的激活函数的演变。第一个CNN模型诞生于1989年,发明人LeCun。1998年,LeCun提出LeNet,并成功应用于美国手写数字识别。这是一种自下向上的一种学习方式,使用的是Tanh激活函数。
设计能够快速训练精确的深层神经网络的激活函数是一个非常活跃的研究领域。目前神经网络最常用的激活函数-ReLU(rectified linear unit)是Nair & Hintonw是在2010为限制玻尔兹曼机(restricted Boltzmann machines)提出的,并且首次成功地应用于神经网络(Glorot,2011)。除了产生稀疏代码,主要优势是ReLUs缓解了消失的梯度问题(Hochreiter,
1998;Hochreiteret al .)。值得注意的是,ReLUs是非负的,因此,它的平均激活值大于零。并且ReLU更容易学习优化。因为其分段线性性质,导致其前传,后传,求导都是分段线性。而传统的sigmoid函数,由于两端饱和,在传播过程中容易丢弃信息。
ReLUs缺点是不能用Gradient-Based方法。同时如果de-active,容易无法再次active。因此,Goodfellow et al., 2013将ReLU和Maxout分段线性的激活函数应用于神经网络,取得了很大得进步。maxout的激活函数计算了一组线性函数的最大值,并具有可以逼近输入的任何凸函数的性质。Springenberg & Riedmiller(2013)用概率max函数代替了max函数,Gulcehre等人(2014)探索了用LP规范代替max函数的激活函数。
“Leaky ReLUs”(LReLUs)用一个线性函数替换ReLU的负部分,在论文(Maas et al.,2013《Rectifier
nonlinearities improve neural network acoustic models.》)中,已被证明优于ReLUs。
PReLUs( Parametric Rectified Linear Unit参数修正线性单元)是由LReLUs衍生,出自论文《Delving
Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet
Classification》。它通过学习负部分的斜率来改进。PReLUs改进模型拟合,额外计算成本几乎为零,且风险较小。此外,PReLUs用了一个鲁棒的初始化方法,特别考虑整流非线性。
另一个变体是Randomized Leaky Rectified Linear Units随机的漏型整流线性单元(RReLUs),它随机抽取负值的斜率部分,提高了图像基准数据集和卷积网络的性能(Xu,et al .,2015)。
与ReLUs相反,LReLUs、PReLUs和RReLUs等激活函数不能保证一个noise-robust失活状态。ELU提出一个具有负值的激活函数,这可以使得平均激活接近于零,但它会以更小的参数饱和为负值。这个激活函数使得代码单元更容易被模型化也更容易解释,只有激活的代码单元携带大量信息。
这个问题目前没有确定的方法,需要结合实际应用情况进行选择。
1)
深度学习往往需要大量时间来处理大量数据,模型的收敛速度是尤为重要的。所以,总体上来讲,训练深度学习网络尽量使用zero-centered数据 (可以经过数据预处理实现) 和zero-centered输出。所以要尽量选择输出具有zero-centered特点的激活函数以加快模型的收敛速度。
2)
如果使用 ReLU,那么一定要小心设置 learning rate,而且要注意不要让网络出现很多 “dead” 神经元,如果这个问题不好解决,那么可以试试 Leaky ReLU、PReLU或者
Maxout。
3)
最好不要用 sigmoid,可以试试 tanh,不过可以预期它的效果会比不上 ReLU 和 Maxout。